I never guess. It is a capital mistake to theorize before one has data. Insensibly one begins to twist facts to suit theories, instead of theories to suit facts. Sir Arthur Conan Doyle, Author of Sherlock Holmes stories
How to Make Twitter Analysis and Virtualize to Data? (Part-1 Collecting Data With Python)
In Data Science, collecting data is the most important part and we can collect data from Facebook,Yelp,Twitter,Linkedin etc.So,in this post I decided to twitter for collecting data because twitter provide us some useful features about data analysis and I think the best useful feature is all tweets can be maximum 140 characters and it’s help us about summarize.On the other hand,twitter is one of the most popular social media in the world and every day more than 300 milyon people visit there.Anyway,I think this introductory sentence is enough so let’s start.
Take a Twitter API Account
To access Twitter we have to create a new account from twitter Api.Enter this website link and click the ‘Create New App’ and it’ll give us like this page : 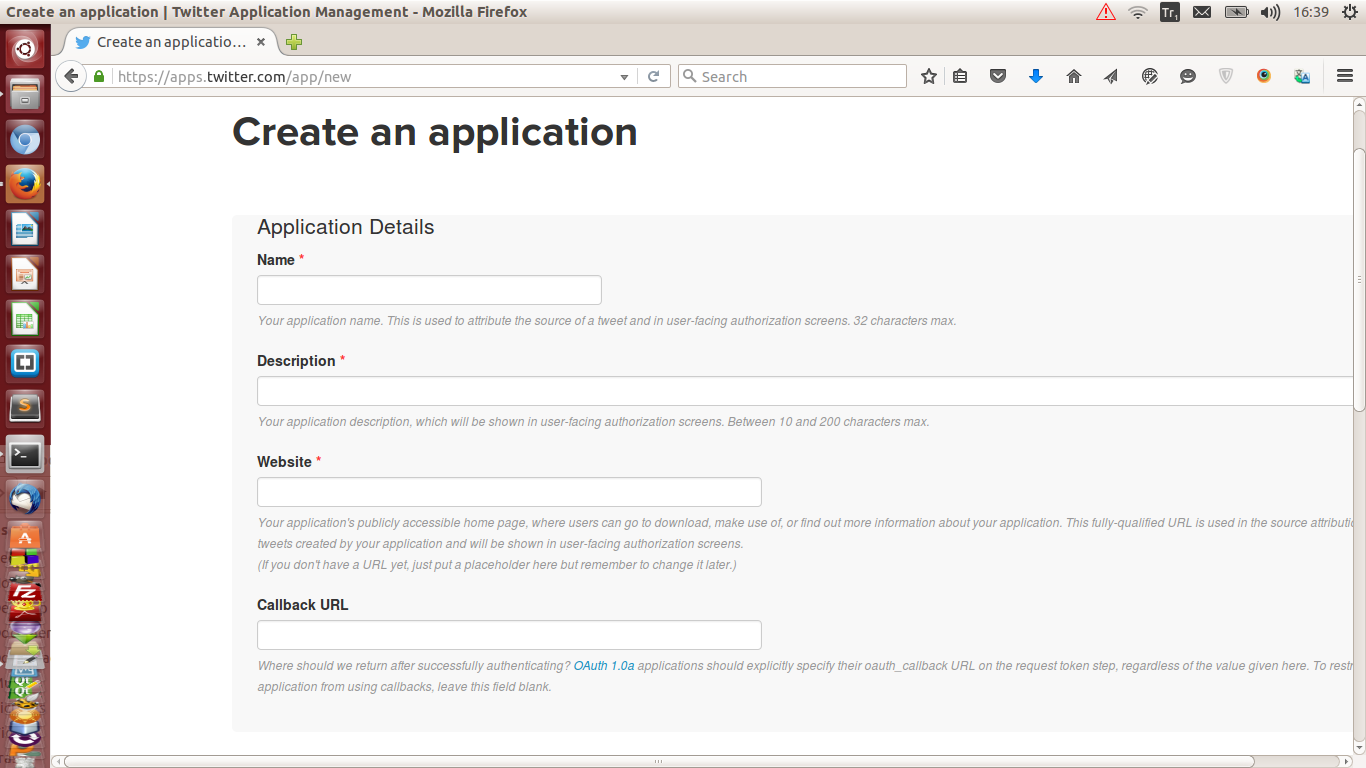 .
.
Name -> Write a name whatever you want.This only shows in twitter app page Description -> Write a something like this Data Analysis Demo Website -> Write localhost
It finished and the last but not the least, keep your consumer_key, consumer_secret, access_token,access_secret_token in your text editor because we’ll need to these information while we’re accessing to Twitter API with Python.
Access to Twitter API With Python
In order to do this, we need to tweepy library. You can install throuh two ways 1)
sudo pip install tweepy2)git clone https://github.com/tweepy/tweepy.git -> cd tweepy -> python setup.py install
**Python 2.6 and 2.7, 3.3, 3.4 & 3.5 are supported.**
Let’s Start Writing Our Python Codes
First of all, we must import our library which using the codes
from tweepy import Stream
import tweepy
from tweepy.streaming import StreamListener
Then, fill out into " " with your own API keys
CONSUMER_KEY = "fill out here"
CONSUMER_SECRET = "fill out here"
ACCESS_TOKEN = "fill out here"
ACCESS_TOKEN_SECRET = "fill our here"
Ultimately, we provide all information to access Twitter api and now let's access
key = tweepy.OAuthHandler(CONSUMER_KEY,CONSUMER_SECRET)
key.set_access_token(ACCESS_TOKEN,ACCESS_TOKEN_SECRET)
We accessed to our Twitter API.Now,we’re going to create a class for collect data.This class includes two function called on_data, on_error . Hence the name, on_data function works if retrieve data from the twitter but it’s not on_error function will work. In on_data function, we’ll keep all tweet in tweets.json file in order to analysis.
class MyListener(StreamListener):
def on_data(self, data):
try:
with open('tweets.json', 'a') as f:
f.write(data)
return True
except BaseException as e:
print("Error on_data: %s" % str(e))
return True
def on_error(self, status):
print(status)
return True
Finally, we’re going collect tweets about We’ll define with twitter_stream.filter function into data.json file by using twitter Stream().You can write whatever you want into track = [] . It’s like twitter search engine.
twitter_stream = Stream(key, MyListener())
twitter_stream.filter(track=['#chelsea','#manu','#liverpool','#everton'],languages=['en'])
I tried and it gave me this result </br>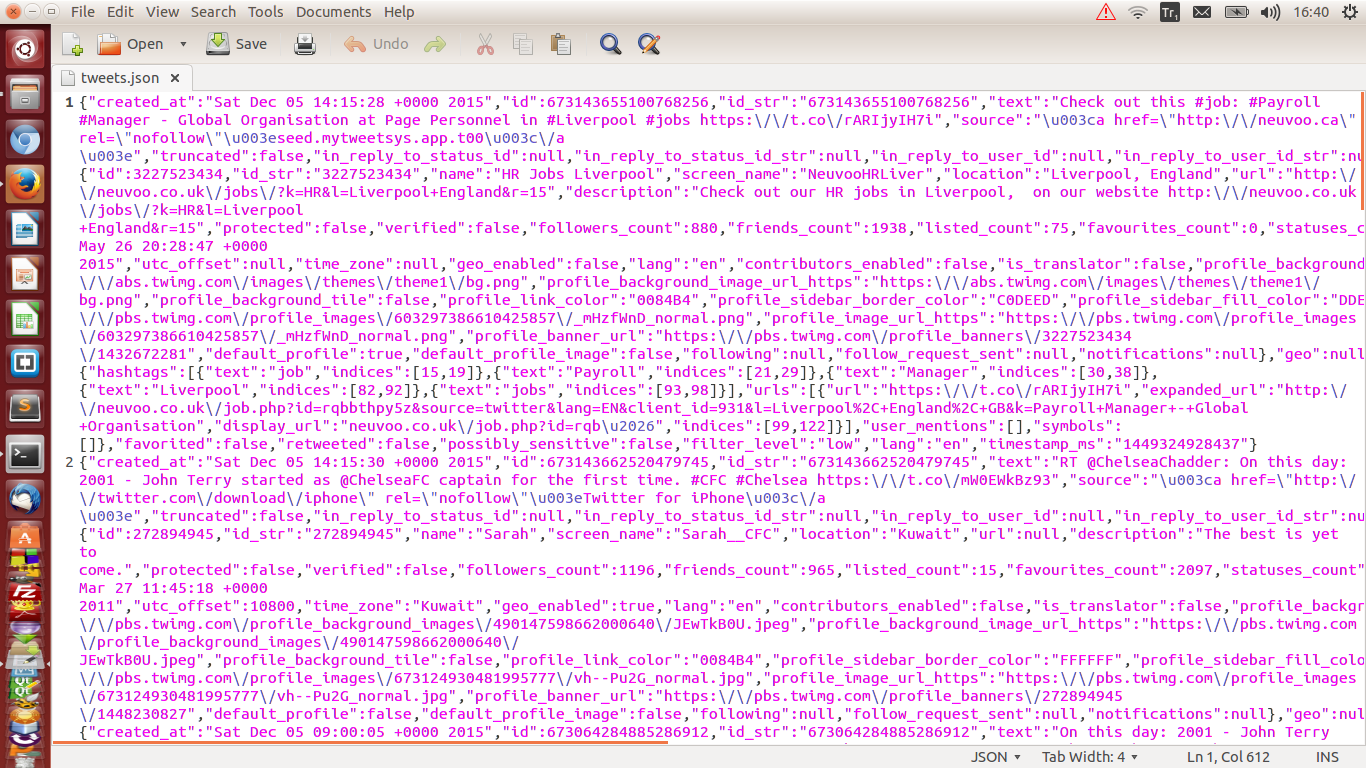 .
</br>As you can see above it works.So,in part-2 I’m going to show How to Analysis this tweets.json file and virtualize.
.
</br>As you can see above it works.So,in part-2 I’m going to show How to Analysis this tweets.json file and virtualize.